May Update
External MCP, agent management, zero-downtime deploys, and a supply-chain hardening pass.
Last month was autonomous agents and the CLI overhaul. The two months since have been about hardening the surfaces around them: agent management got a real UI, the platform learned how to call out to other people’s MCP servers, deploys stopped dropping requests, and the supply chain got signed end-to-end. Spans v0.7 through v0.9.0.
External MCP Client
Agents can now invoke tools on remote MCP servers. Set up an external MCP server in the platform, connect agents to it, and the tools show up in their toolset alongside the built-ins. There’s a connection model for both agent-scoped and user-scoped servers, OAuth handling for the ones that need it, and a panel on the agent for managing what’s wired up.
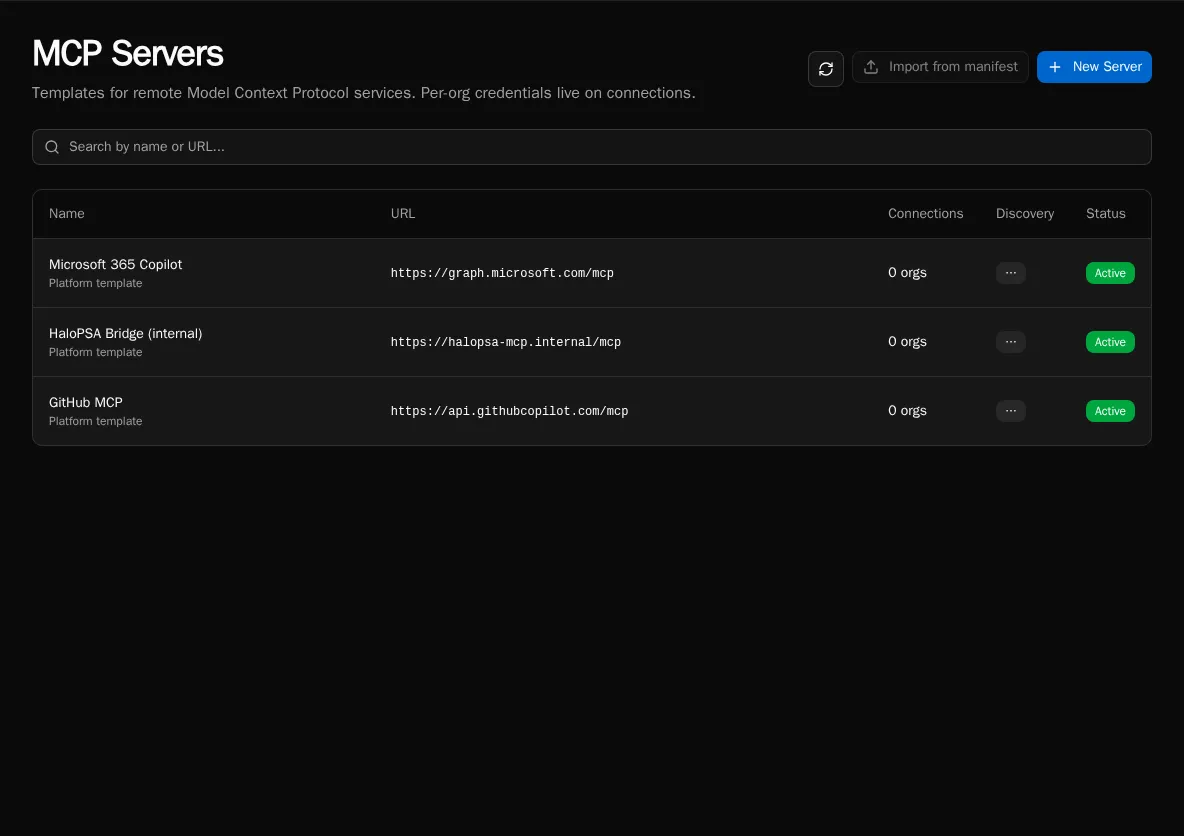
This was contributed by @sdc53 (#177) on top of a v2 spec they also wrote (#176). It’s a substantial piece of work and the kind of contribution that’s hard to overstate. Agents reaching out into the MCP ecosystem instead of being limited to whatever’s defined in your workspace changes the ceiling. Thank you.
Agent Management
The agent surfaces have been rebuilt. There’s now a proper Fleet page, a per-agent detail page, and a tuning workbench where you can iterate on prompts with dry-run impact, save versions, and see history. Run summarization happens automatically after completion with cost tracking, and there’s a backfill endpoint and admin UI for pulling stats on older runs.
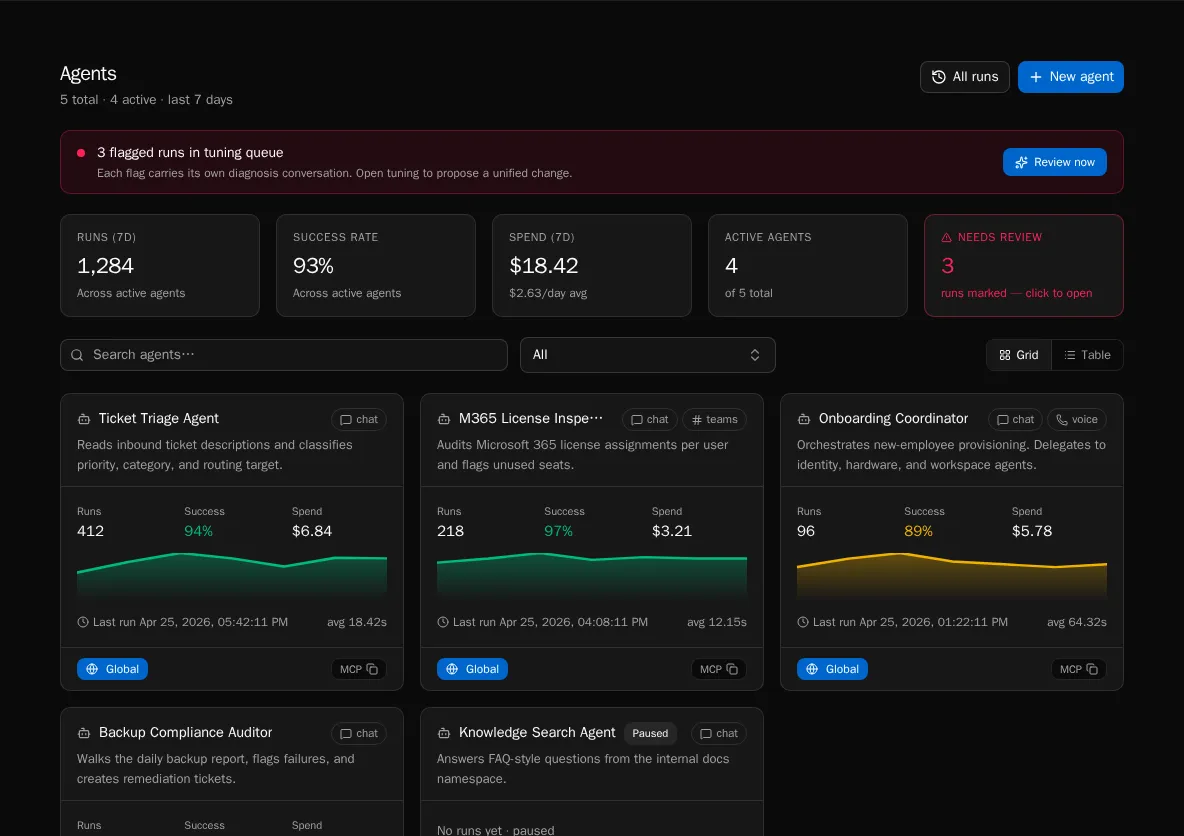
Per-flag tuning. When you adjust a tuning flag, you can have a focused conversation with the system about that flag, dry-run the impact against historical runs, and see what’s about to change before you save. This was the missing piece between “I think this prompt change will help” and actually shipping it.
Cost tracking on chat. Chat conversations now roll up into the same agent stats as autonomous runs (#221). It was strange to have a per-agent cost number that quietly excluded everything anyone said in the chat panel.
Zero-Downtime Deploys
The API now does rolling updates, workers drain instead of dying mid-execution, and the client gets a version banner that prompts a refresh when a new version is up, but only after the old version actually has a successor running, so you don’t get a banner that points at nothing (#174). Plus an AMQP retry layer that papers over the rabbitmq blip during deploys (#194).
As more is running on this in production, deployments dropping requests or workers dying mid-execution becomes a real problem. Now they don’t.
Native Workflow Scheduling
You can schedule a workflow to run at a future time, cancel scheduled runs, and filter execution history by Scheduled. There’s a DateTimePicker in the UI and a Scheduled badge so you can tell what’s coming versus what’s already run.
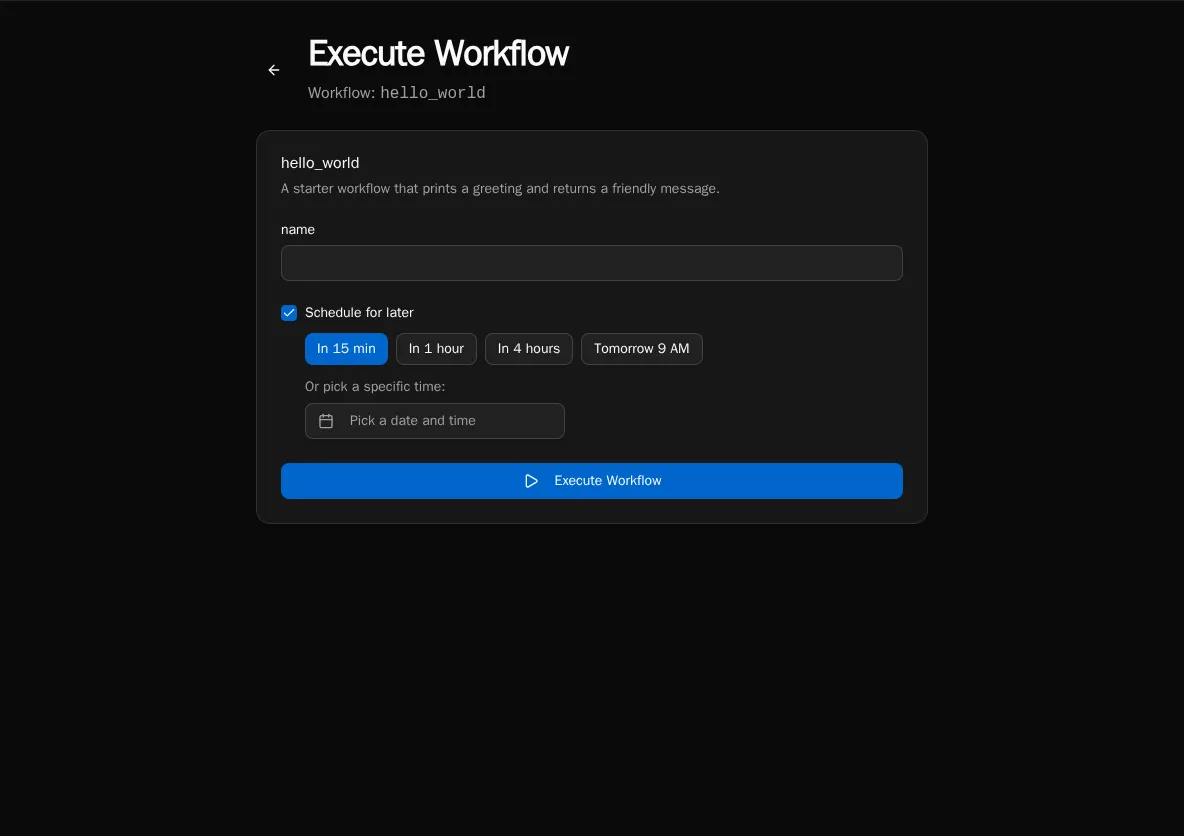
We had this before, but only because we contrived it out of tables and a second workflow that polled them. Now scheduling is native to the workflow primitive itself, available from the UI, the SDK, and the API. The contraption goes away.
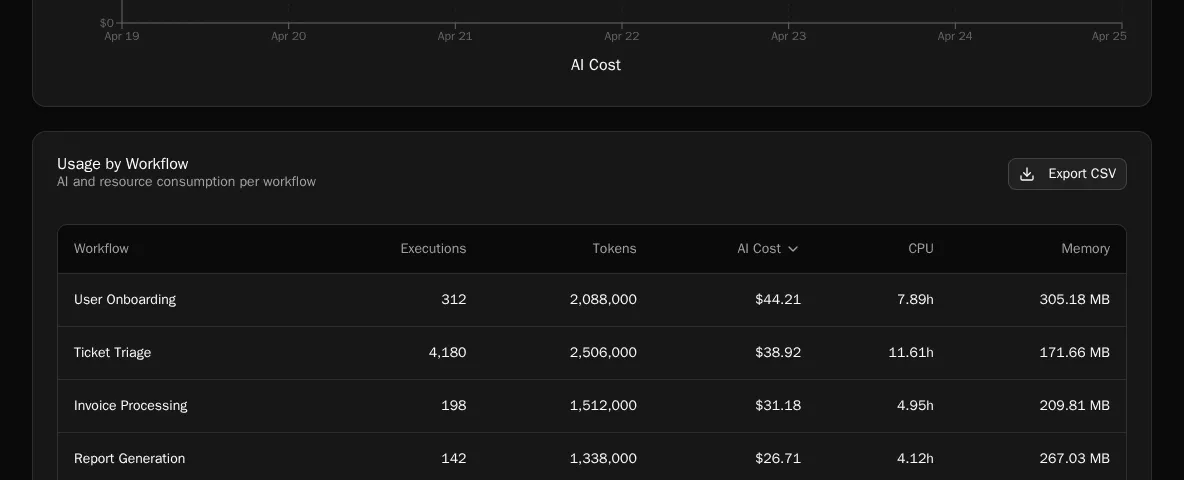
Tables: Access Policies
Tables now have a real access-policy model with a redesigned policy editor (#178). Existing tables get an admin_bypass policy backfilled so nothing breaks (#179). Combined with the access controls now exposed in the CLI for forms and workflows (#163), the multi-tenancy story is starting to feel coherent: the same set of primitives across surfaces, configurable from the SDK.
Skills as a Plugin
The development skills (bifrost-build, bifrost-setup) are now distributed as a Claude Code plugin, with a bifrost skill CLI for installing and updating them (#169). The previous flow involved cloning the bifrost repo and copying directories into your .claude/, which was on my shit list for a while. Now you install once and updates come along for the ride.
Supply Chain Hardening
This is the v0.8.0 headline and it’s the least exciting kind of work. Releases are now signed with Sigstore/cosign keyless OIDC plus a SLSA build-provenance attestation. Container images get the same treatment. Pip dependencies are hash-pinned via requirements.lock. Bifrost earned OpenSSF Best Practices Baseline Level 1.
The honest version: I didn’t sit down one morning and decide to chase a badge. It happened because the code-scanning queue had a long tail of legitimate findings, including log injection, partial SSRF, and a path-traversal bug in LocalBackend._resolve_path where /sandbox and /sandbox_evil would compare equal at the byte level (#80). Working through those one at a time made it cheap to also pin everything, sign everything, and put the badge on the README.
The MCP side got its own pass. There was a cross-tenant access leak where the access gates and the UUID coercion were checked in different orders (#201). Fixed and unified.
CLI: Quality of Life
A pile of CLI work that adds up.
Ephemeral sessions and multi-instance auth (#151). You can be logged into multiple Bifrost instances from the same machine without them clobbering each other, and ephemeral sessions don’t persist credentials beyond the process.
workflows execute over WebSocket (#168). Streams output as the workflow runs instead of polling, plus a requirements group for managing workspace deps from the CLI.
Per-worktree debug stacks (#137). If you’re juggling git worktrees on a feature branch, each one gets its own isolated debug stack so you don’t have ports fighting each other. There’s a bifrost-debug skill that wires this up.
.env from CWD, not pipx venv (#160, #164). The CLI now reads .env from where you ran it, which is what everyone assumed it was already doing.
Stale CLI version actually blocks (#206/#207). The version-check banner is now blocking instead of advisory. If your CLI is too old to talk to the API safely, it stops you.
Bug Fixes Worth Naming
E2E flakes finally closed. Two intermittent test failures had been thrashing CI (#101 was failing 5x in 48 hours, #102 was failing 11x). Root cause was test isolation, fixed via a partial unique index on system_configs plus an autouse reset fixture (#122).
MCP OAuth redirect. Login.tsx was treating absolute return_to URLs as relative paths, so MCP callbacks were getting links like /login/https:/example.com/mcp/callback (#24). Reported with a full root-cause analysis and a proposed fix by @Fireworrks.
Firefox 150 bundle loads. The static import map for shared host modules wasn’t quite right and Firefox 150 was choking on it (#175). Fixed by @Cory-Covi.
OAuth scope on refresh-token exchange (#26), workflow timeout honoring 0 as documented (#27), and K8s readiness probes (#37) all from @MTG-Thomas, who has shown up in every release notes for the last several months. Genuinely appreciated.
Other Things Worth Mentioning
- Forms got a
multi_selectfield type. - Embed supports an explicit
hmac_schemeper secret (shopifyorhalopsa), also from @sdc53 (#23). - Workflow hooks got
errorMessageas a canonical alias and deprecated the oldererror(#166). - Embeddings got an endpoint override and automatic reindex when the model changes (#195), plus batch resilience and accurate reindex status (#199).
- Tailwind compilation for v2 apps with arbitrary values,
@apply,@layer, and per-app config (#143). - Execution hardening: webhook rate limits, schedule overlap detection, stuck-execution recovery (#141).
- Backend deps moved from
requirements.txttopyproject.toml. If you were installing from source, switch topip install -e .fromapi/, orpip install -r requirements.lockfor a hash-verified install (#126).
What’s next
Chat V2 is the near-term focus. The spec is locked and the design preview is in the repo (#138). Conversations with agents are the surface most people actually touch every day, and there’s value in having a native chat interface that tries to keep up.
The bigger-ticket things still on the list:
External agents. Investigating the Microsoft 365 Agent SDK, natively deploying Teams agents, the things MSPs actually care about. The challenge is balancing that against not reinventing what someone else is always going to do better. I don’t have an answer yet.
RBAC. In discovery, but a huge lift. The plan is to turn the platform admin checkbox into an actual role backed by real scopes. Once that’s in, the execution runtime can run as the user who actually called it, with “extra permissions” assigned per workflow. This is the right shape; the work to get there is going to be substantial.
In-app development. Still figuring out the best way to support this. The CLI no longer tries to sync the manifest in realtime, but I want it reliable enough to run predictably from a CLI and ideally a git merge. My ideal is direct edits locked down on the platform side (like disabling push to git main), so changes go through a real CI pipeline. I don’t yet know how that works for developers who need access to integrations. Table policies (and file policies, which are coming) should remove integrations as a hard dependency for a lot of app development, taking out a whole layer.
I’m also looking at clawing org and role assignments back out of workflows and inferring them from page, agent, or form access, the way they used to work. That simplified things quite a bit, especially when RBAC is the thing controlling what a person can do. It still has rough edges around integrations and how much you can trust a page call as an inferred permission.
There’s a lot to think about here. I want to solve it because I want a team of people working on this safely, contributing, merging without unmaintainable logic piling up. The platform is materially more capable than it was in March, and I’d rather take longer on these next questions than ship a half-step. Currently, we have a few people using it with bifrost watch and many of our commits have been around stabalizing issues we’ve had with that. But fundamentally there isn’t anything owning git operations, which is clearly a miss. I’m really looking forward to my ‘aha’ moment on this one.